Architecture brief
RAG vs MCP vs Fine-Tuning LLMs
RAG gives the model fresh knowledge. MCP gives it a standard way to reach tools and systems. Fine-tuning changes how the model itself behaves. Strong products usually combine them instead of treating them like a single winner-take-all choice.
The plain-English answer
These options do not change the same part of the stack. RAG changes what the model knows at run time by pulling in relevant information. MCP changes what the model can reach by standardizing access to tools, data sources, and actions. Fine-tuning changes the model itself by pushing it toward a narrower, more consistent behavior.
That is why teams get confused when they compare them as if they were three competing products. They are three different levers. One fixes stale knowledge. One fixes missing connectivity. One fixes persistent model behavior.
Which layer are you actually changing?
This is the fastest way to avoid picking the wrong technique for the wrong problem.
| Option | What changes | Best fit | Typical failure if you misuse it |
|---|---|---|---|
| RAG | The context available at inference time | Fresh, private, or frequently changing knowledge | Answers still sound polished, but retrieval misses the right document or returns stale context |
| MCP | The model's access to tools, apps, databases, and workflows | Systems that must read from or act inside external software | The model knows what should happen but cannot safely do it |
| Fine-tuning | The model's learned behavior | Stable formatting, taxonomy, style, or narrow task adaptation | Teams retrain the model for a knowledge problem that should have been solved with retrieval |
| Agent loop | The logic that decides when to retrieve, act, retry, or escalate | Multi-step work with checkpoints and recovery | Useful components exist, but the workflow has no control layer |

Start with RAG when the problem is knowledge
RAG is usually the first serious move because most enterprise AI products fail on freshness and access long before they fail on model style.
- Use it when answers depend on current product docs, policies, contracts, support history, research, or internal knowledge that changes too often to bake into model weights.
- Use it when the model needs private business data but you do not want to retrain every time the source material changes.
- Use it for enterprise search, knowledge assistants, document question answering, support copilots, and analyst tools that need current context.
- Do not expect RAG to fix weak workflow control or weak tool integration. It improves grounding, not system reach.
What a real RAG stack includes
A usable RAG system is not just a prompt with a few pasted snippets. It is a data system.
| RAG layer | What it does | What teams usually underestimate |
|---|---|---|
| Query framing | Turns a user request into a retrievable search problem | Weak query expansion, bad filters, and missing metadata make the whole stack look worse than it is |
| Chunking and embeddings | Breaks documents into searchable pieces and maps them into vector space | Chunk size, overlap, and embedding quality decide whether the right evidence is even retrievable |
| Semantic retrieval | Searches by meaning instead of exact keyword match | The index can still drift, grow stale, or surface the wrong slice of a document |
| Integration and prompting | Combines user intent and retrieved context before generation | Too much irrelevant context can hurt just as much as too little context |
| Permissions and freshness | Keeps data current and scoped to the right user | Role-based access, PII controls, stale metadata, and poor refresh jobs are where trust breaks |
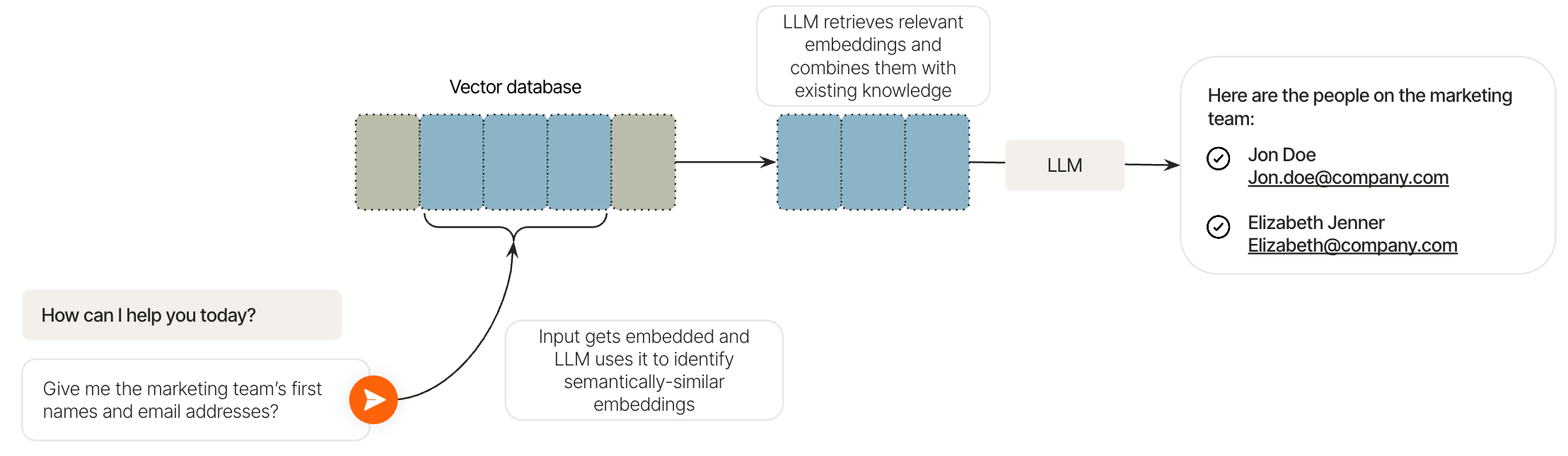
The RAG details teams skip
The hard parts are operational, not conceptual.
- Documents need to be organized, deduplicated, and tagged well enough for search to stay reliable.
- Unstructured content usually has to be chunked before it can be embedded and searched effectively.
- Vector storage helps the system search by meaning, but the surrounding ranking and filtering logic still matters.
- Prompt tuning still matters because the model has to use retrieved context correctly, not just receive it.
- RAG ages badly if refresh jobs lag or if the system keeps indexing low-quality material.
Fine-tuning changes behavior, not the knowledge pipe
Fine-tuning is strongest when the model should respond in a narrower, more consistent way every time. That can mean tone, output structure, taxonomy, domain style, classification behavior, or better performance on a repeated task pattern.
It is weaker as a fix for rapidly changing business facts. If the issue is that the model does not know today's policy update, latest pricing rule, or newest internal manual, retraining the model is usually the slow and expensive answer.
The fine-tuning options that matter
Model customization is not one technique either.
| Method | What it changes | When it fits | Main tradeoff |
|---|---|---|---|
| Supervised fine-tuning | Uses labeled examples to push the model toward desired outputs | Stable formatting, task behavior, specialized classification, domain style | You need clean examples and a clear definition of what good performance looks like |
| Full fine-tuning | Updates the full model more aggressively | High-value narrow use cases where deeper customization is worth the cost | More compute, more maintenance, and slower iteration |
| Parameter-efficient fine-tuning | Updates a smaller slice of the model | When you want meaningful adaptation without paying for full retraining | Less expensive, but still requires disciplined data and evaluation |
| Continuous pretraining | Deepens domain familiarity with new unlabeled data | Broader domain adaptation before task-specific shaping | It improves familiarity with a domain, but it is not the same as task-level fine-tuning |
Choose fine-tuning when the model itself is the bottleneck
This is the right lever only after you are sure the failure is not actually about knowledge freshness or missing tool access.
- Use it when the model must produce a stable output format every time.
- Use it when narrow domain jargon, labels, or task patterns must be learned deeply rather than reintroduced through prompts.
- Use it when the product needs consistent behavior even before any retrieval happens.
- Do not use it as a shortcut for stale documents, weak retrieval, or absent permissions.
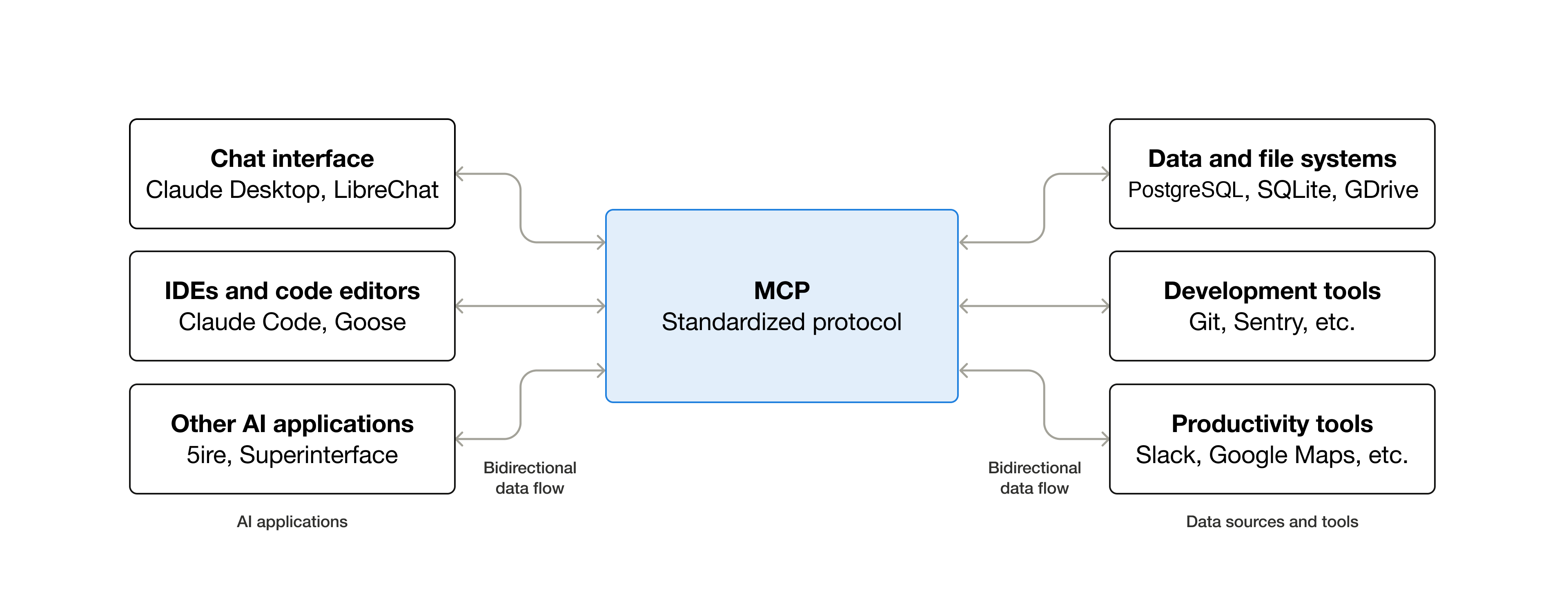
MCP is the connectivity layer
MCP is best understood as a standard port for AI applications. It gives models and agents a consistent way to talk to outside systems instead of forcing every tool connection to be custom-wired. That is why it matters so much for assistants and agents that need to read data, trigger workflows, or operate across SaaS products.
The value is not only technical neatness. Standard connectivity reduces duplicated integration work for developers, expands what AI clients can do, and makes end-user experiences more useful because the model can reach the systems where the real work lives.
What MCP adds to a product
The protocol matters once the model must interact with software, not just talk about it.
| Part | Role | Examples |
|---|---|---|
| Host application or client | The assistant, agent, IDE, or app that asks for data or actions | Chat assistants, coding tools, product copilots, internal workbench apps |
| MCP server | Exposes data or capabilities from a system | Files, databases, APIs, calendars, ticketing systems, design tools |
| Tools | The callable operations surfaced through the server | Create a ticket, search a knowledge base, fetch a record, update an account, send a message |
| Workflow layer | Lets the model chain tool calls into useful work | Planning tasks, stepping through approvals, interacting with multiple systems in one run |
Use MCP when the model must act
This is where the difference between knowledge access and software execution becomes obvious.
- Use it when a user wants the assistant to create a ticket, send an email, update a customer record, or read from multiple business systems.
- Use it when the same AI product should work across files, apps, databases, calendars, and internal tools without a different custom interface for each one.
- Use it when agents need standardized tool access rather than a pile of one-off integrations.
- Do not treat it as a substitute for retrieval quality. MCP can expose systems, but it does not automatically make the model well-grounded.
Where agents fit
Agents sit above these choices as the workflow layer. They decide when to retrieve more context, when to call a tool, when to ask a human for approval, and when to stop. That is why the best production stacks often look like RAG plus MCP plus an agent loop instead of a single clever technique.
This hybrid view also explains a common mistake. Teams sometimes think MCP makes RAG unnecessary or that fine-tuning removes the need for system design. In practice, stale indexes still damage retrieval, weak permissions still damage tool use, and poor workflow control still damages outcomes. The techniques complement each other; they do not erase each other's failure modes.
Choose the stack by product shape
Architecture gets easier when you map it to the product you are actually building.
| Product type | Likely core stack | Why |
|---|---|---|
| Internal knowledge assistant | RAG first, optional agent layer | The core problem is grounded answers from changing internal information |
| Support or operations agent | RAG plus MCP plus agent layer | It needs current knowledge and the ability to create, update, or route work |
| Domain-specific writing or classification tool | Fine-tuning plus optional RAG | The persistent behavior of the model matters more than live system actions |
| Enterprise search product | RAG first | Search quality, freshness, and permissions are the main engineering problem |
| Cross-app workflow bot | MCP plus agent layer, often with RAG | The value comes from reaching systems safely and sequencing work across them |
Decision rule in one minute
If the debate is getting abstract, reduce it to these checks.
- If the model is missing current facts, start with RAG.
- If the model needs to do something in another system, add MCP.
- If the model keeps behaving the wrong way even with the right context, evaluate fine-tuning.
- If the product spans multiple steps, retries, approvals, or tool choices, add an agent layer on top.
Frequently asked questions
These are the practical questions teams usually mean when they search this topic.
Should an enterprise knowledge assistant start with RAG or fine-tuning?
Usually RAG. If the problem is current or private knowledge, retrieval is the natural first layer. Fine-tuning only becomes the better answer when the model's stable behavior is the real issue.
Is MCP a replacement for RAG?
No. MCP standardizes connectivity to tools and systems. RAG improves grounded answers by supplying relevant context. Many strong products need both.
Can MCP retrieve data too?
Yes, but that does not make it equivalent to a well-designed retrieval stack. You still have to solve freshness, permissions, filtering, and how the model uses what it receives.
When does fine-tuning beat RAG?
When you need consistent behavior, formatting, labeling, or domain-specific task performance that should hold across prompts instead of being rebuilt from retrieved documents every time.
What does a strong production architecture usually look like?
A common pattern is RAG for knowledge, MCP for tool connectivity, and an agent layer for orchestration. Fine-tuning gets added only when the base model still behaves too generically after the other pieces are in place.